
Maskinlæring med Titanic (oppgave)#
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# Les dataene
# ...
Utforsking og opprydding av datasettet#
La oss undersøke dataene og rydde litt, dersom vi trenger det.
# Skriv ut de fem første linjene
# ...
Vi ser at det ikke er alle kategoriene vi trenger. Siden vi er interessert i hvem som overlevde, og hvorfor, kan det også være lurt å sjekke hvor mange dette var. Du kan beregne sum og antall av et dataframe-element ved å bruke metodene .sum() og .count() på elementet (f.eks. titanic[‘age’].sum()).
# Sjekk hvor mange som overlevde
# ...
# Slett kategorier du mener er irrelevante for overlevelse med datarammenavn.pop("navn på kolonne")
# ...
Vi kan også undersøke manglende verdier og eventuelt sette inn representative verdier der det mangler.
# Printer ut antall manglende verdier i kolonnene
print(titanic.isna().sum())
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
class 0
alive 0
alone 0
dtype: int64
# Fyller inn manglende alder med gjennomsnittet
gjennomsnitt = titanic['age'].mean()
titanic['age'].fillna(gjennomsnitt, inplace = True)
I hvilke sammenhenger kan det være legitimt å gjøre som ovenfor? Var det legitimt i denne sammenhengen?
Visualiseringer#
La oss først se hvilken effekt klasse og kjønn hadde på overlevelsessjansene:
# Passasjerklasse
sns.countplot(x='pclass', hue='survived', data=titanic, palette='ocean')
plt.title("Antall døde (0) og overlevende (1) av hver klasse")
plt.xlabel("Klasse")
plt.ylabel("Antall")
plt.show()
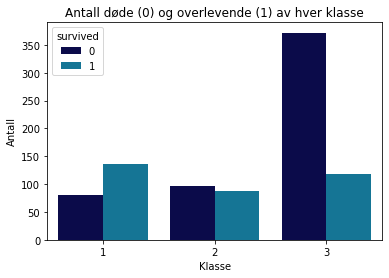
# Lag et tilsvarende plott som viser hvilken effekt kjønn hadde på overlevelsessjansene.
Vi ser, ikke overraskende, at menn på 3. klasse hadde særdeles dårlige odds. Vi har alderen til passasjerene, men ikke alderskategorier. Lag alderskategorier for barn og voksen, og lag en ny kolonne kalt “aldersklasse”.
# Sortere etter alder
aldersklasse = []
for alder in titanic['age']:
### fyll inn kode her.
titanic['aldersklasse'] = aldersklasse
# Plott effekten aldersklasse har på overlevelse
Maskinlæring#
Vi skal nå lage en modell som kan forutsi hvorvidt en person overlever på Titanic eller ikke, gitt data om personen. Vi velger ut hvilke data vi ønsker å bruke som kriterium for overlevelse, og spesifiserer kategorien “survived” som målkategorien vår:
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn import tree
from sklearn.metrics import accuracy_score, confusion_matrix
kriterier = titanic[[# Legg inn kriterier (kolonnekategorier) for overlevelse her]]
kategorier = # legg inn kategori her
I maskinlæring er det viktig at modellen vår klarer å forutsi data som kommer utenfra datasettet vi trener modellen med. Derfor deler vi ofte opp dataene i et treningssett og et testsett. Treningssettet bruker vi til å trene modellen, testsettet til å teste og evaluere modellen i etterkant. Vi blander ikke disse dataene. Vi kan generere slike data med funksjonen train_test_split(). Her bruker vi 80 % av dataene til trening og 20 % til testing. Du bør bruke minst 70 % av dataene dine til trening.
# Del opp datasettet ditt i trenings- og test-kriterier og trenings- og testkategorier.
Forklar hva funksjonen train_test_split gjør ut fra programmet ovenfor.
Hva er poenget med separate treningskriterier og testkriterier?
Nå kan vi lage modellen vår. Vi bruker en algoritme som heter Decision Tree Classifier. Det er basert på sammensatte og forgreinede valgtrær, der alle kombinasjoner av kriterier blir utforsket. Betingede sannsynligheter for ulike hendelser blir beregnet, og de mest sannsynlige utfallene blir framhevet basert på kombinasjonen av kriteriene. Først trener vi modellen:
# Opprett og tren modellen her
DecisionTreeClassifier()
Det var det - da har vi en modell! Den ligger nå i et objekt som vi har kalt modell. Vi kan få innsyn i hvordan modellen ser ut, men det kan fort bli litt uoversiktlig og teknisk. La oss først nøye oss med å sjekke hvordan modellen takler testsettet vårt.
Forklar med ord hva du tror modellen gjør når den “trener”.
Test og validering av modellen#
La oss nå bruke modellen for å forutsi hvem som overlever og hvem som ikke gjør det:
# Regn ut accuracy score for å validere modellen her
0.7597765363128491
Hva sier dette resultatet deg?
For å få bedre oversikt over hva modellen forutsier riktig og hva den feiler på, kan vi konstruere en såkalt “Confusion Matrix” (forvirringsmatrise/feilmatrise):
cm = confusion_matrix(modellkategorier_forutsett, testkategorier)
import seaborn as sns
sns.heatmap(cm, annot=True, cmap='viridis')
plt.title("Forvirringsmatrise")
plt.xlabel("Predikerte verdier")
plt.ylabel("Sanne verdier")
plt.show()
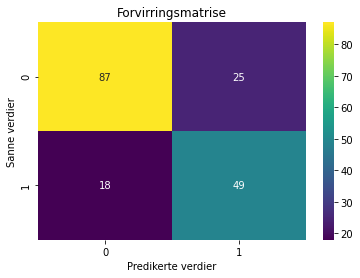
Hva forteller diagrammet ovenfor oss?
Vi kan benytte disse dataene til å beregne hvor stor prosentandel av overlevende og døde som modellen klarte å forutsi korrekt.
# Beregn andelen korrekt forventet død og korrekt forventet overlevelse.
Sammenlikn størrelsen på disse andelene. Hva er eventuelt årsaken til at det er en forskjell på dem?
La oss helt til sist visualisere modellen vår. Vi velger maks dybde på modellen til 2 for at vi ikke skal få alt for mange forgreininger.
plt.figure(figsize=(20,10))
titanic.pop('survived')
tree.plot_tree(modell, max_depth=2, feature_names=titanic.columns, class_names=['Døde', 'Overlevde'], filled=True, label=None,)
None
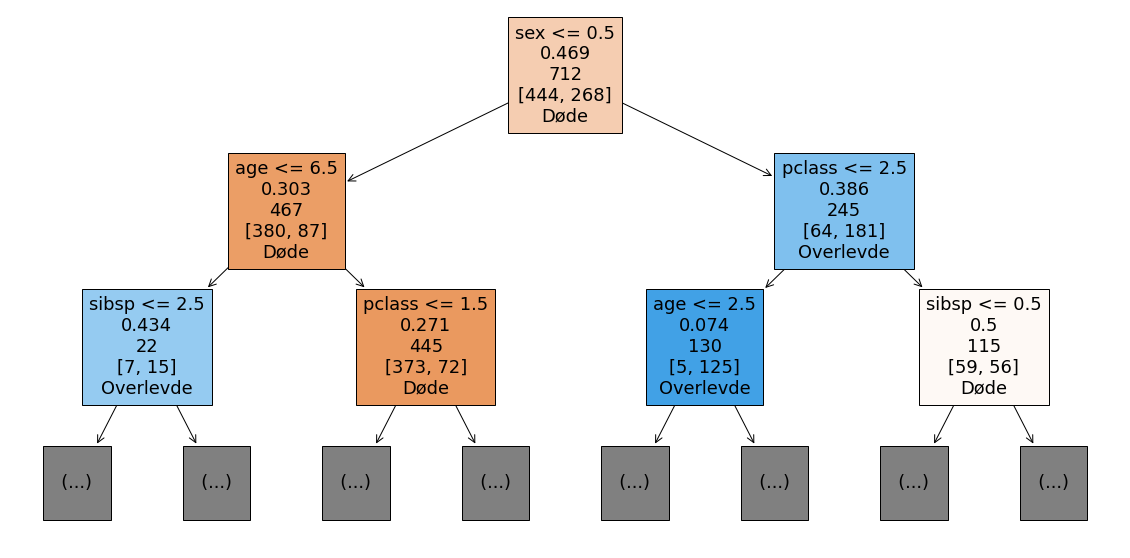
Bruk visualiseringen av modellen ovenfor til å forklare hvordan modellen vår fungerer.
Lagre og åpne modellen vår#
Vi kan også lagre modellen vår, slik at vi kan bruke den seinere:
filnavn = "titanicmodell.sav"
joblib.dump(modell, filnavn)
modell = joblib.load(filnavn)